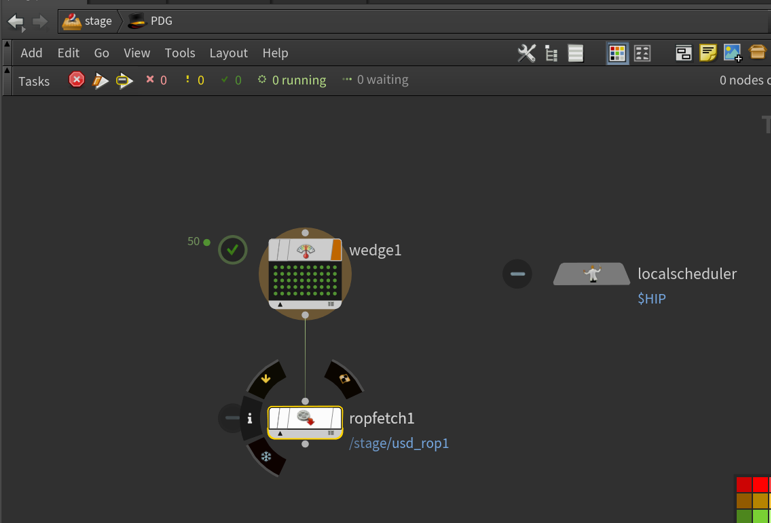
Over the past few months, I have been experimenting with ways to create concept art tools using StyleGAN ADA. One of these experiments failed brutally. Rather than focus on the successes of the other experiments, I decided to focus on the one that was going the poorest and see if I could fix it with synthetic data in Houdini.
My initial goal was to create a GAN that generated character concept art silhouettes. I had no lofty goals, just to create a Rorschach-esque GAN that created blobs that were informed by the common shape languages of character design.
THE FAILED EXPERIMENT:
I spent an unreasonable amount of time scouring the internet for roughly 1000 images to train on. Here is a small sample of those training images.
After collecting and formatting them with photoshop actions, I trained on them for a few hundred tics. these were the results.
As it continued training It devolved into this.
INFORMAL ANALYSYS:
My expectations were low but even I was unimpressed with this. The blobs were only vaguely humanoid and more importantly they had very little variety.
There were tons of things wrong with the way I trained. I honestly didn't have nearly enough training data. Training a GAN on only 1000 images is kind of a ridiculous expectation but, I'm only one person and I'm making do with the images I can get my hands on.
Rather than try to find more data like any reasonable person, I applied my "animation tutor" brain to think about what the GAN needed to learn, and why it was failing to learn it.
I observed that it appeared to be getting the texture of the art right, my guess was that it was lacking an understanding of anatomy. I also thought it was unlikely that the GAN would learn the underlying anatomy that guides concept art just by looking at the concept art itself because, concept art tends to hint at the forms, allowing the viewer to complete it, rather than crisply portraying it. I'm sure the GAN would eventually learn but it would take much more data.
THE NEW PLAN:
Make thousands of pieces of synthetic data portraying anatomically correct silhouettes. Train the GAN on the synthetic data, then use transfer learning to retrain it on the concept art afterwards.
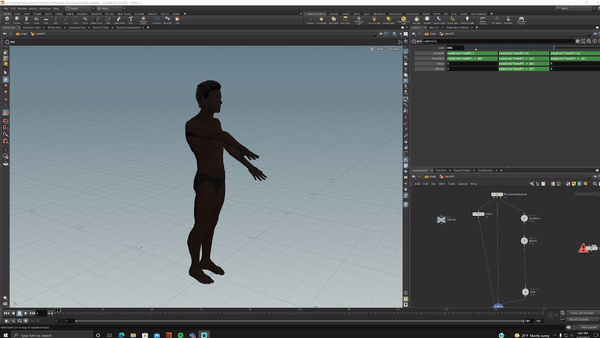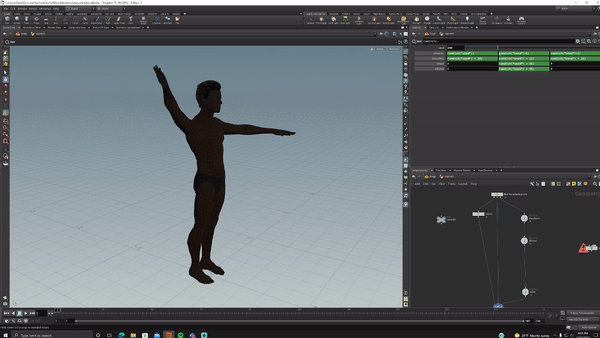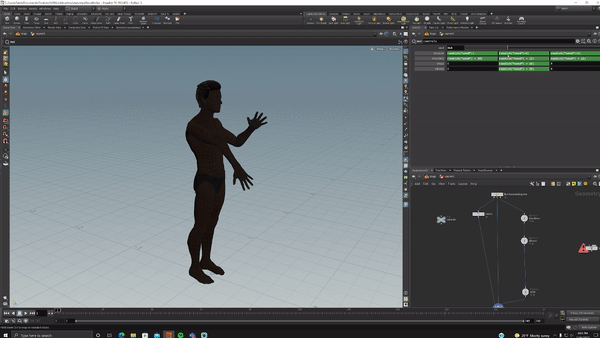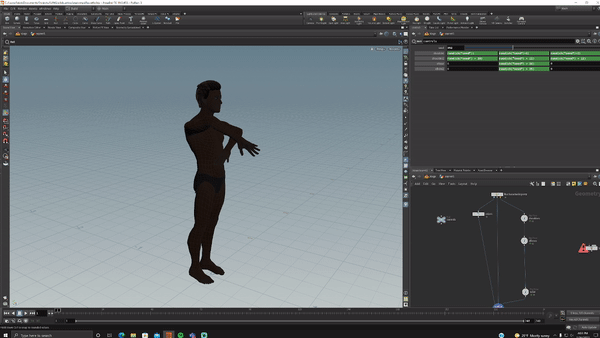
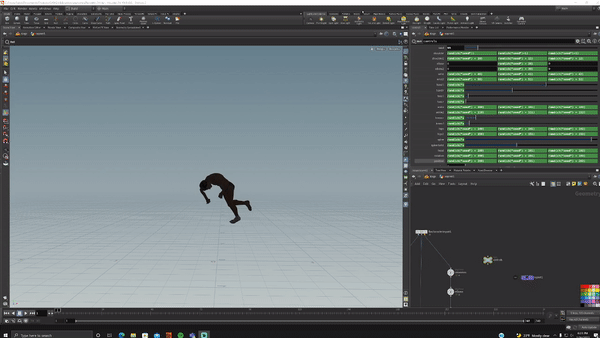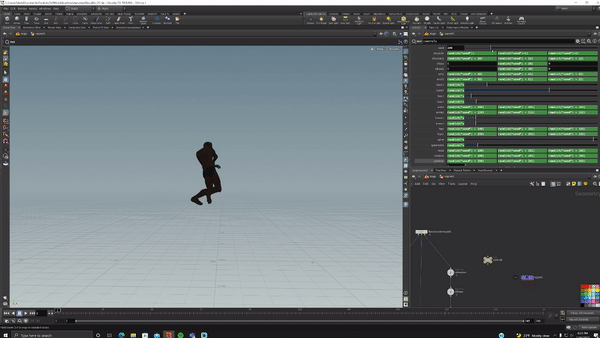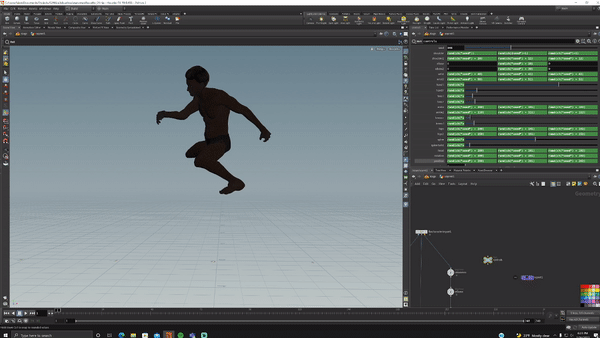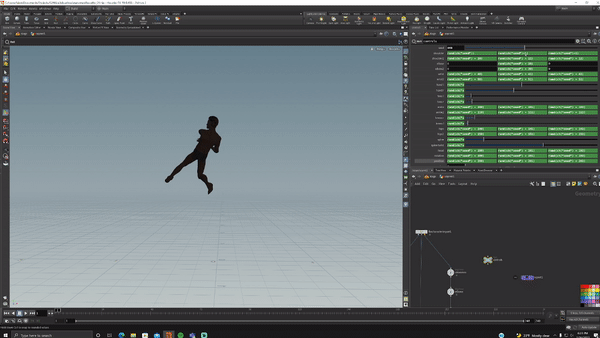
I bought a 15-dollar rig from Turbosquid, opened Houdini, set up acceptable ranges of motion for each joint in KineFX then randomized all of them.
fig. 1 "surely not EvErY oNe was kung fu fighting?"
fig. 2 "the actual data I used to train"
I hit render and generated 5000 randomized versions of this (I love proceduralism <3).
NOTE: This entire process of creating and rendering took significantly less time than gathering the initial data. The Houdini work took me probably 4 hours.
I ran the training for 1000 tics on the synthetic set and got results like this.
pretty dang humanoid if you ask me.
Then I used transfer learning to re-train the same network on the concept art silhouettes
Sheeeeeesh! Thats like 1000x better than the last one.
Here is a side-by-side comparison:
without synthetic data with synthetic data
It honestly blows my mind how well the training went after synthetics were added. Not only did the forms become more humanoid, the results also included more variation in pose and body proportions. I was also a bit surprised that none of the results looked like the crappy synthetic silhouettes that I had done pre-training on.
Here is the original concept art used to train again for comparison:
TL; DR:
Augmenting training with synthetic data allowed me to train a GAN on a very small sample of real data and improve results dramatically
DISCLAIMER:
I am completely unqualified to do any of these experiments or write about them in an academic fashion. I have a BA in Motion Design.